Authors:
(1) Nicholas Farn, Microsoft Corporation {Microsoft Corporation {nifarn@microsoft.com};
(2) Richard Shin, Microsoft Corporation {eush@microsoft.com}.
Table of Links
Conclusion, Reproducibility, and References
D. Nuances comparing prior work
4 EXPERIMENTS AND ANALYSIS
4.1 EXPERIMENTS
We evaluate GPT-3.5 (gpt-3.5-turbo-0613) and GPT-4 (gpt-4-0613) on ToolTalk using the functions functionality as part of OpenAI’s Chat completions API (OpenAI). This API takes as input an optional system message, a history of messages between a user and an assistant, tool documentation, and any previous tool invocations and their responses, and produces as output either a tool invocation or an assistant message.
In the system message, we include the conversation’s location, timestamp, and (if present) username. We supply documentation for all 28 tools at once to simulate a user with all 7 plugins enabled. We then simulate and evaluate all conversations in the easy and hard subsets of ToolTalk, following Algorithms 1 and 2.
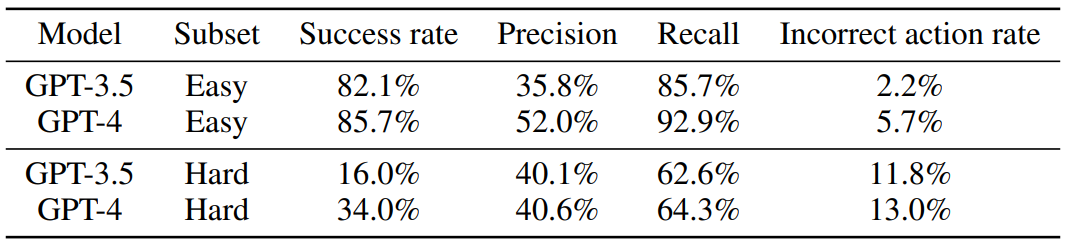
Table 1 shows the results. We get success rates of 85.7% and 92.8% for GPT-3.5 and GPT-4 on the easy version of ToolTalk, and success rates of 26.0% and 50.0% on the hard version. GPT-4 outperforms GPT-3.5, but still achieves similar incorrect action rates. From precision, we can see that GPT-4 is also more efficient than GPT-3.5. However, performance for both models are low, showing the difficulty of tool usage in conversation settings.
4.2 ANALYSIS
We analyze the conversations that either GPT-4 or GPT-3.5 fail on. We notice that for both LLMs, there are three major reasons that they can fail. First, the model may predict a tool call prematurely on a turn before a user has provided the necessary information. Second, the model may exhibit poor planning, resulting in omitting or using the wrong tools. Third, it may have picked the correct tool to use, but invoked it with incorrect or missing arguments, failing to follow the tool’s function signature described in the documentation. GPT-3.5 is more susceptible to these errors, but they manifest as well for GPT-4.
Premature tool calls. This usually occurs when the user has a clear intent, e.g. “I want to create an event”, but has yet to provide the necessary information to provide as arguments. It then manifests as hallucinating plausible values to supply as arguments. This is harmless when predicting reference tools but is a direct contribution to failure when predicting action tools. Concerningly, even when the hallucinated arguments will result in execution errors, the model will persist in hallucinating more arguments. Despite these issues, both GPT-3.5 and GPT-4 will generally choose the correct tools to accomplish the intent.

Faulty reasoning. Ultimately, premature tool calls could be mostly explained by faulty reasoning, where the LLM fails to reflect that it does not have all the information it needs to accomplish a task and needs to ask the user to provide more clarification. Similarly, omission or the usage of wrong tools can also be explained by faulty reasoning skills; rather than reflecting and realizing it needs to ask the user to provide more clarification, the LLM fails to realize that it needs to call additional tools in order to accomplish a task.
For example, the SendEmail tool requires a recipient email address, which can be obtained from a username with the QueryUser tool. However, instead of using QueryUser and then passing its result to SendEmail, the model may instead hallucinate a plausible email address belonging the user. In other circumstances, the model will forget specifics of the task and fail to call the corresponding tools. For example, if a user wants to both send a message and change their calendar, the model will only change the calendar and not send the message. In egregious cases, both LLMs can hallucinate tools or not predict any tool usage at all and confidently state that it has accomplished the task.
Incorrect invocations of the correct tool. Even if the model picks the correct tool, it can invoke the tool with incorrect arguments, by missing values or supplying wrong values. This can happen from failing to understand documentation, failing to understand the output of previous tool invocations, or weak mathematical skills. Examples include supplying 2 PM as “2:00” instead of “14:00”; calculating a 10 hour event ending at 6 PM as 6 PM to 12 AM; incorrectly supplying a reminder it had just created to the DeleteReminder tool.
Quantitative results. Table 2 shows the number of turns in which the above error types occur, in our evaluation of GPT-4 and GPT-3.5. We determine error types automatically by comparing predictions for a single turn with the ground truth for the same turn and seeing which predictions and ground truth tool calls fail to find a match. GPT-4 overall produces fewer errors for each category than GPT-3.5. However, GPT-4 generally fails for the same reasons as GPT-3.5 in cases where both fail on the same conversation. GPT-4 does demonstrate a clear improvement in planning over GPT-3.5 as GPT-4 will generally be able to determine all tools needed to accomplish a task.
Lessons. Our results and analyses suggest a few ways to improve tool usage and design for LLMs. Some form of self-reflection or grounding for argument values seems key to reduce premature invocation of tools. This can also help LLMs determine if it has all the tools necessary to complete a task. For GPT-3.5 in particular, minimizing the number of arguments in tools seems likely to lead to good improvements. This is because unlike GPT-4, GPT-3.5 has more difficulty recovering from errors, often giving up.
4.3 EXPERIMENT REMOVING DOCUMENTATION
We perform an ablation study to measure the effect of tool documentation by removing all tool and parameter descriptions keeping only names and parameter types. We re-evaluate GPT-3.5 and GPT4 on ToolTalk producing Table 3. We also re-run our analysis on error types producing Table 4. Performance on ToolTalk significantly decreases across the board except for incorrect action rate. The decrease in incorrect action rate could be due to tools being harder to use, resulting in less successful tool executions overall, whether or not it matches ground truth.
From Table 4 we can see that faulty planning accounts for the majority of errors produced by GPT3.5 and GPT-4. We perform a qualitative analysis and discover both models tend to call tools with incorrectly formatted arguments, receive errors in execution feedback, then persist in the same incorrect format. This results in both models eventually giving up and predicting an assistant reply thereby missing all other tool calls in the ground truth.