
Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
3.2.1 Introduction
In-context few-shot learning seeks to solve unseen tasks at inference time by conditioning on a few training examples. In particular, in this case we are interested in methods that forgo any weight updates (Brown et al., 2020). Prior work has been focused on improving inference time algorithms (e.g., rescoring generated outputs (Zhao et al., 2021), selecting (Liu et al., 2021) and ordering (Lu et al., 2021) the given few-shot examples) and incorporating extra resources (e.g., finetuning models on human-annotated datasets (Mishra et al., 2021; Ye et al., 2021; Wei et al., 2022)).
We hypothesise that a different way to improve in-context few-shot learning is through designing self-supervised objectives that more closely resemble the format of tasks that the model will be asked to perform. To do so, we cast the self-supervised training as an intermediate training stage between language model pretraining and downstream few-shot evaluation. In particular, we construct training datasets based on the self-supervised objectives following similar formats used in the downstream tasks, finetune pretrained language model checkpoints on the training datasets, and then evaluate the models on benchmarks.
In experiments, we consider four self-supervised objectives, including masked word prediction and classification tasks related to next sentence prediction (Devlin et al., 2019). We evaluate models on two benchmarks (13 tasks in total): SuperGLUE (Wang et al., 2019) and Natural-Instructions (Mishra et al., 2021). SuperGLUE focuses on discriminative tasks, and Natural-Instructions is a set of generative tasks.
Empirically, we experiment with pretrained language models of two sizes: 125 million parameters and 1.3 billion parameters. We show that in our best setting, the 1.3 billion parameters model trained by the self-supervision performs better than the initial pretrained language models and two strong baselines on average.
Further analysis reveals that (1) the effectiveness of the self-supervision depends on the amount of training data, but the benefit of adding more data is diminishing; (2) the improvements brought by the self-supervision are in part due to the semantic similarity between the training and evaluation tasks; (3) adding more self-supervised objectives may not help model performance because adding them does not contribute to the diversity of the self-supervised tasks; (4) choosing similar task templates for both self-supervised and downstream tasks plays a vital role in improving model performance; (5) self-supervised tasks and human-annotated datasets are complementary; (6) generation examples show that compared to the initial pretrained language models, self-supervised-trained models are better at following the task instructions.
3.2.2 Related Work
In-Context Few-Shot Learning. Brown et al. (2020) discover that large pretrained language models can solve unseen tasks at inference time. Recent work has improved the in-context few-shot performance by rescoring generated outputs (Zhao et al., 2021), selecting (Liu et al., 2021) and ordering (Lu et al., 2021) the given fewshot examples. Other work studies pretrained language models’ cross-task generalization abilities for in-context few-shot or zero-shot learning using human-annotated datasets (Ye et al., 2021; Wei et al., 2022; Sanh et al., 2022; Min et al., 2021; Xu et al., 2022) via instructions (Weller et al., 2020; Efrat and Levy, 2020; Mishra et al., 2021; Ouyang et al., 2022) and retrieved examples (Hu et al., 2022; Lin et al., 2022). Our work differs in that we focus on self-supervised training.
Finetuning for Few-Shot Learning. Pretrained language models for few-shot learning typically follows the “pretrain then finetune” paradigm (Howard and Ruder, 2018; Radford et al., 2018; Devlin et al., 2019, inter alia), where recent work has focused on designing templates for few-shot finetuning (Reynolds and McDonell, 2021; Schick and Schutze ¨ , 2021a,c,b; Le Scao and Rush, 2021; Tam et al., 2021; Gao et al., 2021; Sorensen et al., 2022), and optimizing soft prompts (Li and Liang, 2021; Qin and Eisner, 2021; Lester et al., 2021; Gu et al., 2021; Zhang et al., 2022). Other work focuses on unifying task formats to maximize the benefits of human annotations, including question answering (Zhong et al., 2021b), textual entailment (Yin et al., 2019, 2020b; Wang et al., 2021b), and many other tasks (McCann et al., 2018; Keskar et al., 2019; Raffel et al., 2020b; Bragg et al., 2021). In contrast, our focus is on in-context few-shot learning, without finetuning models on downstream task examples.
Pretraining for Few-Shot Learning. Several papers have adapted various resources for pretraining models to enhance their performances on few-shot learning, such as pretraining on hypertext (Aghajanyan et al., 2021b), question-infused pretraining (Jia et al., 2021), and self-training (Du et al., 2021; Vu et al., 2021; Wang et al., 2021d). Pretraining approaches have targeted specific tasks, such as task-oriented dialog (Mi et al., 2021), intent detection (Zhang et al., 2021), and data-to-text generation (Chen et al., 2020e). Our work differs as we use plain text as opposed to (naturally-occurring) human-annotated resources. Relatedly, Bansal et al. (2020) used self-supervised meta-learning for few-shot text classification rather than incontext few-shot learning.
Intermediate Finetuning. Since our approach involves an extra training stage between pretraining and downstream evaluation, it is also related to prior work that uses multi-stage finetuning on human-annotated datasets for generic tasks (Phang et al., 2018; Pruksachatkun et al., 2020; Chang and Lu, 2021; Aghajanyan et al., 2021a; Poth et al., 2021) and text classification (Zhang and Zhang, 2021). Relevant work also studies intermediate finetuning using crosslingual supervision (Phang et al., 2020; Moghe et al., 2021). Rubino and Sumita (2020) use an intermediate self-supervised training stage for machine translation quality estimation.


3.2.3 Method
We describe four self-supervised training objectives that will be used to train models before downstream evaluations.
We begin by defining the example and the instance used during our self supervised training. An example is an input-output pair. To differentiate the input and the output, we append special tokens “Input:” and “Output:” to the beginning of input text and output text respectively where the two texts are also separated by the <newline> token (see Fig. 3.1 for examples).[2]
An instance is a linearized string formed by several examples from the same task (e.g., see Fig. 3.2). As we encode the text using causal attention, the examples closer to the beginning of input sequences can be seen as task demonstrations, resulting in efficient computation.
When constructing the training examples, we pick three or more consecutive sentences (depending on the minimum sequence length we enforce on the sentences) and then apply task-specific rules to automatically create training data. To form a training instance, we randomly select examples from the same task until reaching the maximum sequence length (i.e., 2048). During training, we compute a crossentropy loss on tokens in the output texts. We describe details of the self-supervised tasks as follows.
Next Sentence Generation. In light of the strong performance of language models on in-context few-shot learning (Brown et al., 2020), we incorporate the language modeling as one of our self-supervised tasks, which we call “next sentence generation” (NSG). NSG asks the model to generate the next sentence given previous sentences as context. When building data for this task, we use the last sentence as output and the rest of the sentences as input.
Masked Word Prediction. The second task we consider is based on masked word prediction (MWP) which is commonly used in pretraining generic text encoders (Devlin et al., 2019; Liu et al., 2019). The task asks the model to fill in the missing information based on the surrounding context. Specifically, MWP randomly replaces words in input sentences with a special symbol and requires models to recover the masked words in the input. For this task, we create input text by randomly replacing 1∼20 words in the input text with a special token[3] and use the masked out words as the output text.
Last Phrase Prediction. Inspired by the LAMBADA dataset (Paperno et al., 2016), a question answering dataset which asks models to predict the last word in a sentence given several sentences of context, we create a “last phrase prediction” (LPP) task, which requires predicting the last phrase in a sentence. To solve this task, models need to draw relevant information from the context and the learned knowledge during pretraining. We cast LPP as either a generation task or a classification task. The latter variant of LPP is a binary classification task that labels if the given answer is the correct phrase. To facilitate a unified format of these two tasks, we append a special token “Question:” to the beginning of the last sentence and replace the last phrase with a question mark. For the classification LPP, we separate the given answer and the previous context and sentences with a special token “Answer:”. An example of this task is shown in Fig. 3.1.
More specifically, we identify the last phrase of a sentence based on a set of function words (see Appendix A.3 for the list of function words). If there are multiple function words in a sentence, we pick the last one. Then we treat the text segment starting from the function word as the last phrase.[4] When selecting negative answers, we randomly choose from the phrases extracted from the same function words (to make the negative answers more challenging).
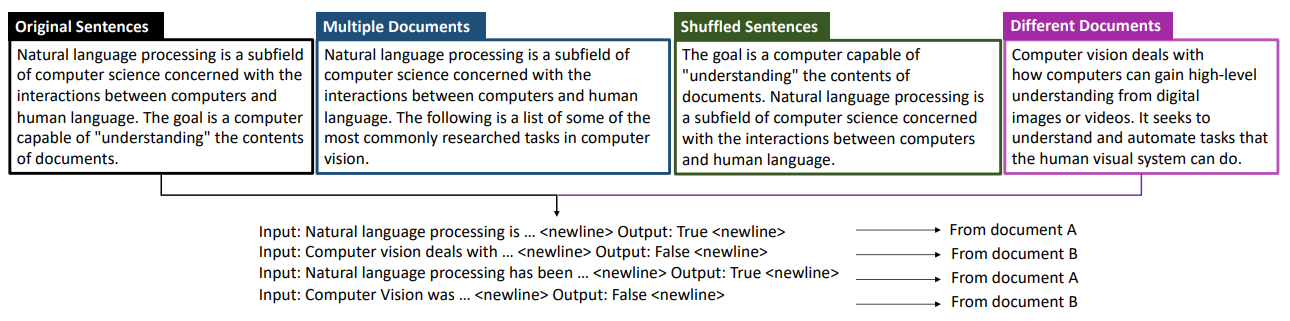
Classification. Similar to the next sentence prediction task (Devlin et al., 2019) and the sentence ordering prediction task (Jernite et al., 2017; Chen et al., 2019b) for pretraining language representations, we create a classification task (CL) for our selfsupervised training. As shown in Fig. 3.3, for this task, we consider four types of input: original sentences, shuffled sentences, sentences from a different document, and sentences from multiple documents. In particular, for original sentences, we directly use text from original human-written documents. For shuffled sentences, we randomly shuffle all the input sentences. For sentences from multiple documents, we randomly replace 50% of the input sentences with sentences from another document. We also ensure that the selected sentences (from both the input and another document) are consecutive in their original documents. For sentences from different documents, we replace the input sentences with sentences from another document. See Fig. 3.3 for an example of each type of input.
When constructing a training instance, we randomly pick one or two additional input types and combine them with the original sentences to form a binary or threeway classification task. We also randomly assign label strings to input types in each instance to ensure that models follow the information given by earlier examples when making predictions.
The classification task is different from the other self-supervised tasks described in earlier subsections. It explicitly requires models to compare inputs across examples in a training instance to determine if the given input shares similar properties with the others.
3.2.4 Experimental Setup
Training Setup. For the pretrained language model checkpoints, we use the 125 million parameters (125M) and the 1.3 billion parameters (1.3B) dense model from Artetxe et al. (2021). These pretrained models have shown results comparable to GPT3 across various tasks.
For self-supervised training, we use a subset of documents from the RoBERTa training corpus (Liu et al., 2019) that contains four domains: BOOKCORPUS plus Wikipedia, CC-NEWS, OPENWEBTEXT, and STORIES. Specifically, we randomly sample 100k documents from each domain except STORIES where we only sample 10k documents as the documents there are much longer than the others. The final training data contains approximately 1 million instances with 250k training instances per task.[5] For the 125M model, we train for 10 epochs, which takes roughly 1 day on a V100 GPU. For the 1.3B model, we train for 5 epochs, which takes roughly 3 days on 2 V100 GPUs.
Evaluation Setup. The instance and example during evaluation shares similar definition as those in Section 3.2.3 except that each evaluation instance has only one example from test splits and it is placed at the last position in the instance. The other examples in the instance (i.e., task demonstrations) come from either training splits or task-specific instructions depending on benchmarks.
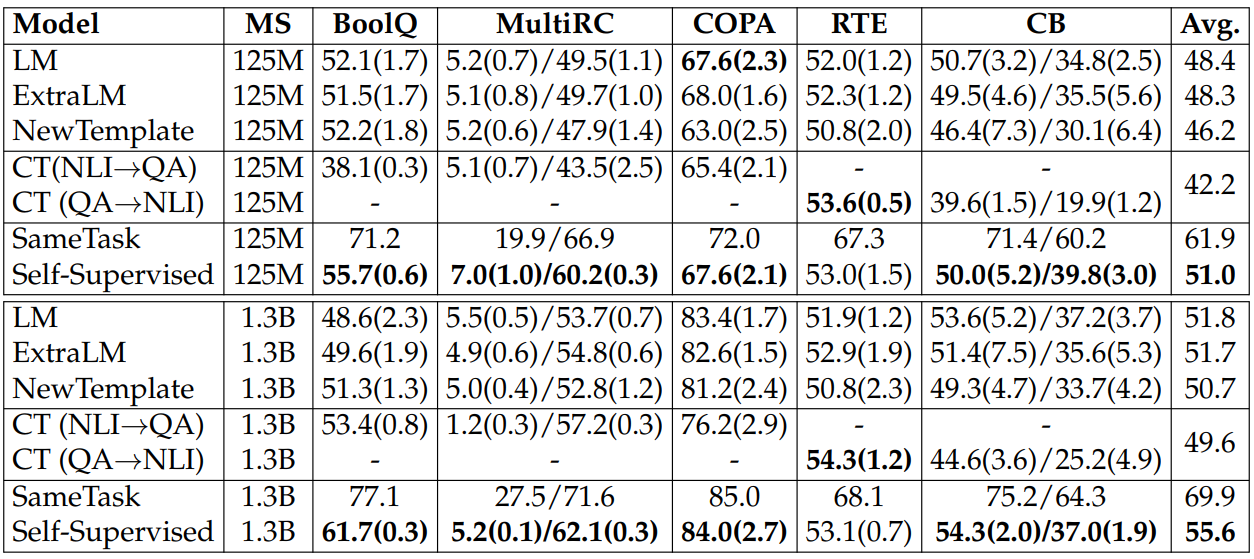
We evaluate the models on two benchmarks: SuperGLUE and NaturalInstructions. SuperGLUE is a set of tasks focusing on natural language understanding. We use BoolQ (BQ; Clark et al., 2019), CB (De Marneffe et al., 2019), COPA (CA; Roemmele et al., 2011), MultiRC (MC; Khashabi et al., 2018), and RTE (RE; Giampiccolo et al., 2007; Bentivogli et al., 2009; Dagan et al., 2006; Bar-Haim et al., 2006).[6] We report results for the official development sets. The task demonstrations are examples randomly selected from the training sets. We report mean and standard deviations of five runs with different random seeds. Following GPT3, we use a ranking based approach when evaluating the models (i.e., pick the best label based on language modeling perplexities).
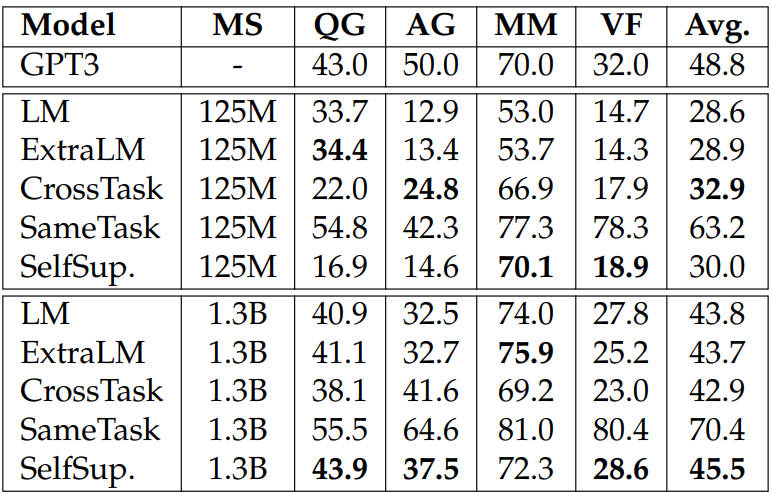
Natural-Instructions evaluates models’ cross-task generalization abilities where all the tasks are generation tasks. It splits the tasks into two groups for training and evaluation. We use the same task split and evaluate models on the following task categories: question generation (QG), answer generation (AG), minimal modification (MM), and verification (VF).[7] Each task category has two tasks. Following the few-shot setting used in Mishra et al. (2021), we evaluate models using 100 examples per task, use greedy decoding, and report ROUGE-L (Lin, 2004) scores per task category. For task demonstrations, we use the positive examples in the instructions in Natural-Instructions.
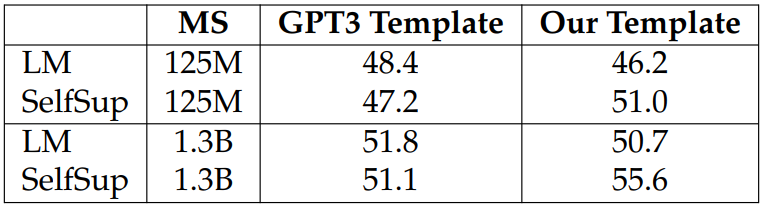
As our self-supervised tasks are formatted as input-output pairs, we change the task-specific templates for SuperGLUE to make them more similar to our selfsupervised tasks. For example, as shown in Table 3.5, we make MultiRC similar to the classification LPP. More details of the template changes are in Appendix A.5.

For both benchmarks, we also report an averaged performance for each model. For SuperGLUE, the average performance is computed based on the means of task performances. When a task has two metrics, we take the average of the two as the task performance.
More details on the dataset statistics and metrics for each task for both benchmarks are in Appendix A.4.
Baselines. We consider four baselines: (1) directly evaluating pretrained language models on the benchmarks (LM) ; (2) performing additional language modeling training on the subset of the original data that is used for constructing the selfsupervised tasks (ExtraLM). We use ExtraLM to approximately measure the contribution of additional computation; (3) fine-tuning on training sets for the tasks outside the evaluation sets (CrossTask). We use CrossTask to estimate the performances of cross-task supervision from human-annotated datasets; and (4) fine-tuning on training sets for the tasks in the evaluation sets (SameTask). SameTask serves as an oracle baseline estimating the approximated upperbound performances of crosstask supervision.
Since SuperGLUE does not have an official split for the CrossTask setting, we split the datasets into two groups according to the task category and report the CrossTask results based on “CrossTask (QA→NLI)” and “CrossTask (NLI→QA)”.[8] As we alter the task templates, we report results for evaluating the pretrained language model
checkpoints using the new templates (NewTemplate) to study the effect of new templates.
3.2.5 Experimental Results
We report the results for SuperGLUE and Natural-Instructions in Tables 3.6 and 3.7. Our findings are as follows:
-
Our proposed self-supervised training achieves the best performance on average for both benchmarks.
-
ExtraLM and NewTemplate show similar performances as the pretrained language model checkpoints, suggesting that the improvements from our self-supervised training is unlikely to come from the additional training on the data and the task template changes.
-
Compared to the pretrained language model checkpoints, CrossTask shows worse performances on both benchmarks, which is likely due to the differences between training tasks and evaluation tasks.
3.2.6 Analysis
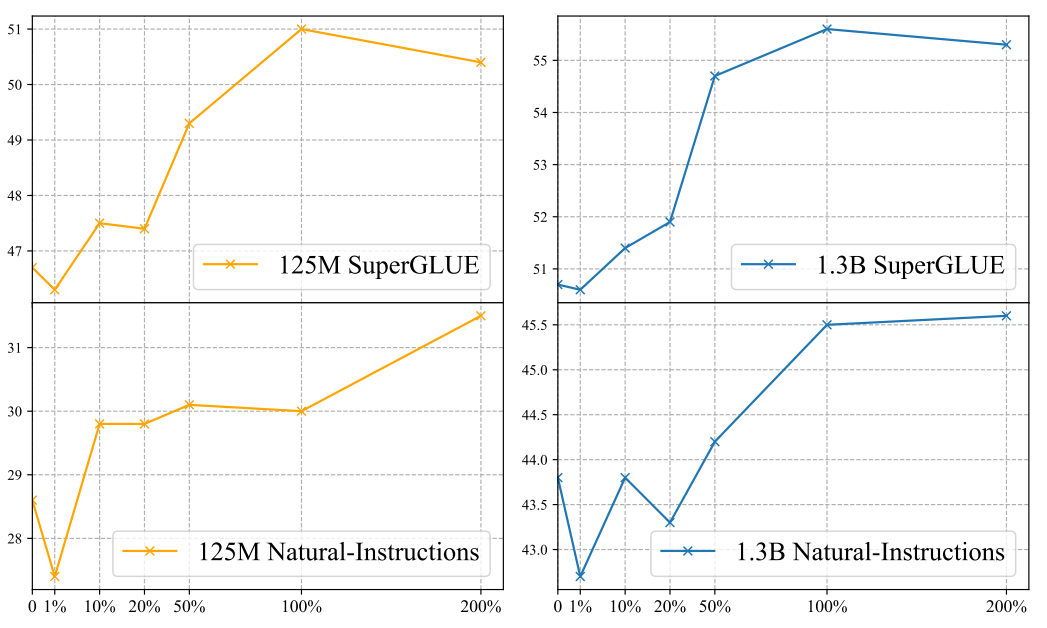
Effect of Amount of Data. In Fig. 3.4, we report model performances for the 125M and 1.3B models on SuperGLUE and Natural-Instructions with 1%, 10%, 20%, 50%, and 200% of training examples.[9] We train the models for ten epochs.[10] As shown in the figure, when the amount of training data for self-supervised tasks is similar to that for the CrossTask setting (i.e., 1% data), the self-supervised tasks also lead to worse performances. The improvements become clearer when we increase the number of training data but it begins to plateau at around 100% data. This suggests that one of the advantages of the self-supervised tasks compared to the tasks in the CrossTask setting is the amount of training data. We hypothesize that further increasing the amount of data not being helpful is because the data used for constructing the self-supervised tasks has already been used for language model pretraining. So, our models manage to learn to solve these tasks with a relatively limited amount of data. We have similar observations for the 125M model.[11]
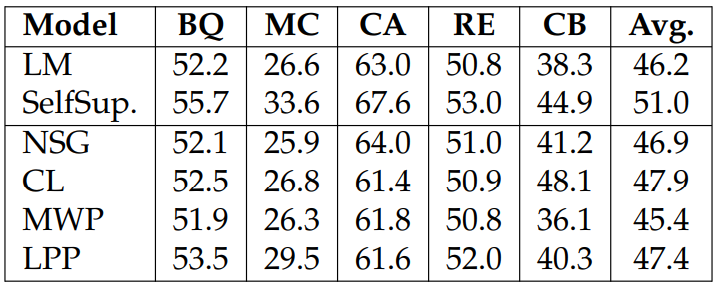
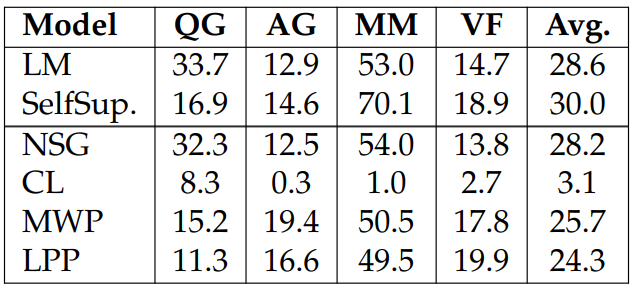
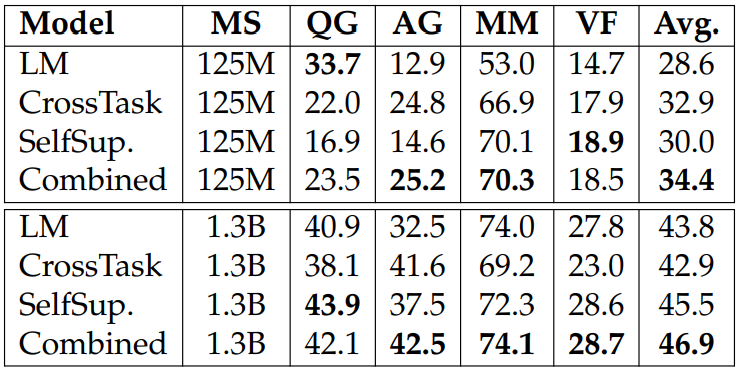
Effect of Individual Self-Supervised Tasks. We investigate the effect of individual self-supervised tasks by training models with only one task. We report the experiment results in Tables 3.9 and 3.10. Our findings are:
-
Combining all four self-supervised tasks results in the biggest improvements for most tasks, suggesting that the tasks are complementary.
-
Each self-supervised task improves a few downstream task performances (e.g., NSG helps COPA; CL helps MultiRC and CB). This is likely due to similarities between tasks.
-
It is worth noting that while CL hurts model performances on NaturalInstructions, it helps on the SuperGLUE. We hypothesis that this is because unlike Natural-Instructions, SuperGLUE is ranking based and, therefore, more favorable to classification-related training.
-
It is interesting to see that NSG and CL tasks are the two most beneficial to downstream performance among the four self-supervised tasks. This is likely due to (1) the generic task formulation of NSG, and (2) CL requires different inference abilities compared to the other self-supervised tasks. It is also interesting that training on only one of the self-supervised tasks can hurt the performance on Natural Instruction.
Effect of More Self-Supervised Tasks. To investigate the effect of having more selfsupervised tasks during training, we add two extra self-supervised tasks to the selfsupervised training, following the same procedure as the other tasks. The additional tasks are: denoising autoencoding (Lewis et al., 2020b) and gap sentence generation
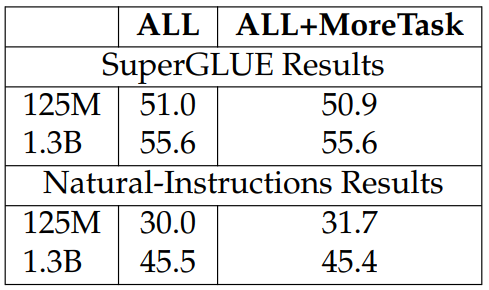
(Zhang et al., 2020a). Denoising autoencoding is the task of reconstructing the original sentences from sentences corrupted by random noises, which has been shown effective for training generic language representations; gap sentence generation is to recover the missing sentence and has been found useful for abstractive summarization.
We report the results in Table 3.11 where we do not find adding the two tasks improves downstream tasks. This is likely because the two tasks share similarities with our existing tasks (e.g., gap sentence generation shares a similar inference style as MWP). So, adding them does not promote diversity in the self-supervised tasks, leading to the fact that the models are not encouraged to learn different information.
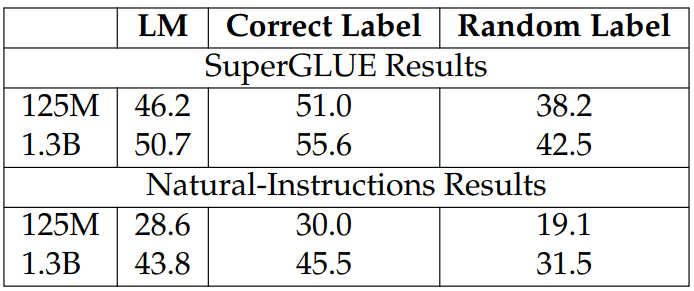
Effect of Few-Shot Templates. The self-supervised training brings two benefits: making models familiar with the few-shot templates and task semantics. To differentiate the effect of the two, we train models on the self-supervised tasks with random labels. For example, for NSG, we use random sentences as outputs rather than the true next sentences; for the binary classification tasks, we randomly select binary labels. As shown the results in Table 3.12, random labels hurt model performances, suggesting that what the models have learned is more than the few-shot format.
We also investigate the effect of task templates for SuperGLUE by evaluating models using different templates. We report results in Table 3.8 where we find that having the templates for downstream tasks similar to the ones used for pretraining gives the models significantly better performance.
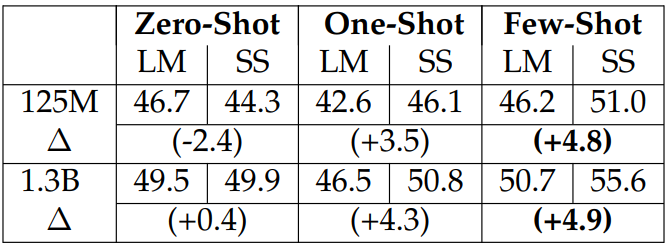
Zero-Shot vs. One-Shot vs. Few-Shot.
Generation Examples. We show zero-shot, one-shot, and few-shot performances for the LM and the self-supervised model in Table 3.13. We find that among the three settings, the self-supervised training is the most helpful in the few-shot setting and does not help in the zero-shot setting, suggesting that the self-supervised training improves the models’ in-context learning capabilities.
Combine Self-Supervision with Cross-Task Human-Supervision. We investigate the relations between the self-supervised tasks and the human-annotated tasks. We combine the tasks from the self-supervision and those from the CrossTask and report the results in Table Table 3.14. Interestingly, combining the two kinds of tasks results in better performances on average, showing that they are complementary.
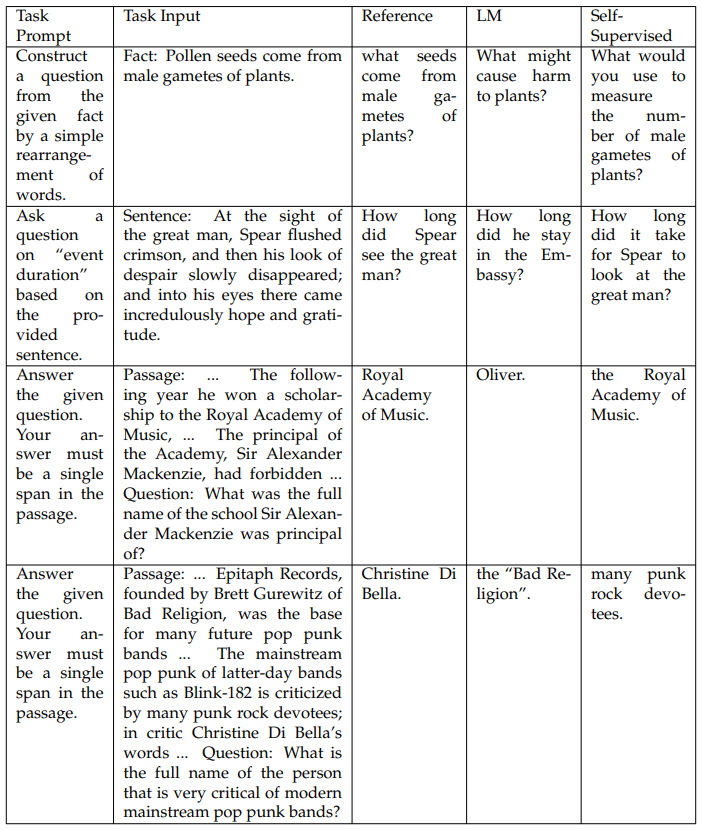
We show generation examples in Table 3.15. In general, we find that compared to the vanilla pretrained language models, the self-supervised models are better at using information from task input following task requirements. Specifically, for the first two examples in Table 3.15, the LM suffers from more severe semantic drift than the self-supervised model (e.g., “male gametes of plants” is more specific and relevant to the task input than “plants”). We have similar observations for the third example, where “Oliver” is a name from the task demonstration rather than the passage. Interestingly, for the last example, the answer generated by the LM is from the passage but is actually “the base for many future pop punk bands” instead of what the question looks for (i.e., “very critical of modern mainstream pop punk bands”). While the answer generated by the self-supervised model does not exactly match the reference, it is partially correct as the mainstream pop punk “is criticized by many punk rock devotees”.
This paper is available on arxiv under CC 4.0 license.
[2] We chose this special symbol because we always start the self-supervised training from a pretrained language model checkpoint.
[3] We randomly select the special token from the following list: , <<>>, @@@, (()), $$$, %%%, ###, ***, and +++. We use random symbols instead of a fixed symbol because we found that it gives better performance in our preliminary experiments.
[4] We ensure that the last sentence in raw text for this task always has at least one valid function word and the function word lies at the second half of the sentence.
[5] The average numbers of example per instance for each data source are: 6.9 for BOOKCORPUS plus Wikipedia, 5.3 for CC-NEWS, 3.5 for OPENWEBTEXT, and 7.2 for STORIES.
[6] We exclude WSC (Levesque et al., 2011) and ReCoRD (Zhang et al., 2018) as pretrained models, including GPT3, require scoring algorithms at inference time to achieve competitive results. We exclude WiC (Pilehvar and Camacho-Collados, 2019) because GPT3-like models, including GPT3 and our models, do not give accuracies significantly better than random baselines.
[7] We discard training tasks that share the same source datasets with evaluation tasks as we found that tasks with the same source dataset may contain leaked labels. We exclude the binary classification tasks because the class labels are severely imbalanced (i.e., more than 80% of the class labels belong to one category).
[8] “QA→NLI” suggests that we train models on the NLI tasks and evaluate on the QA tasks. Similarly, for “NLI→QA”, we train models on the QA tasks and evaluate on the NLI tasks.
[9] We apply the same ratio to all the self-supervised tasks and use the same development sets for each task across these settings.
[10] Upon manual inspection, we found that the development set loss values in these experiments have converged.
[11] Our goal for this analysis is to show the rough trends of model performance when varying the amount of training data, rather than to provide an exact estimate of the training data required for the self-supervised training.